O que é o Hadoop ?

O
Hadoop é um projeto de software livre desenvolvido pela Apache Software Foundation
( http://apache.org/ ), que é uma plataforma de computação distribuida, com alta
escalabilidade, grande confiabilidade e tolerância a falhas.
A
biblioteca de software Hadoop (http://hadoop.apache.org/)
é um framework que permite o processamento distribuído de grandes
conjuntos de dados através de clusters de computadores usando
modelos de programação simples. Ele é projetado para garantir
larga escalabilidade partindo de um único servidor até um cluster
com milhares de máquinas, cada uma oferecendo capacidade de
computação e armazenamento local. Em vez de confiar em hardware
para proporcionar maior disponibilidade, a própria biblioteca foi
concebida para detectar e tratar falhas na camada de aplicação, de
modo a fornecer um serviço com alta disponibilidade baseado em um
grid de computadores.
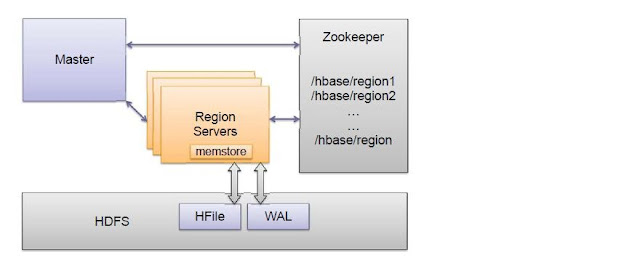
Além
da biblioteca base escrita em Java, chamada Hadoop Common , temos
o HDFS (Hadoop Distributed File System), o YARN e o MapReduce que é
um sistema voltado para processamento de dados com alta
escalabilidade e paralelismo. Podemos criar programas em Java usando
a biblioteca MapReduce (org.apache.hadoop.mapreduce.*) para processar
grandes quantidades de dados em poucos segundos. Realizar uma
operação de sort (ordenação) usando o Hadoop já leva menos de 60
segundos. Além de executar programas em Java, podem ser executadas
funções em Ruby, Python e Pipes (C++).
Nos
próximos posts continuamos a detalhar mais Hadoop, MapReduce e HDFS.


Comentários
Postar um comentário